Submission
Notes: SignalP is
automatically run on all sequences. A warning is displayed if a signal peptide
is not detected. In transmembrane proteins, only extracellular domains may be
N-glycosylated. This is currently not checked by the NetNGlyc server.
Cytoplasmic and transmembrane sequence regions may be predicted to be glycosylated
- this should, of course, be ignored. One transmembrane region predictor is
TMHMM.
Restrictions:
At most 2,000 sequences and 200,000 amino acids per submission; each sequence
not more than 4,000 amino acids.
Confidentiality:
The sequences are kept confidential and will be deleted after processing.
CITATIONS
For publication of results, please cite:
Gupta R, Brunak S.
Prediction of glycosylation across the human proteome and the correlation to protein function.
Pac Symp Biocomput. 2002;:310-22.
PMID: 11928486
Instructions
In order to use the NetNGlyc server for prediction on amino acid sequences:
- Enter a sequence (or multiple sequences in FASTA format) in the sequence window.
Alternatively, give a file name containing sequences in FASTA format (multiple
sequences allowed).
The sequence must be written using the one letter
amino acid code:
`acdefghiklmnpqrstvwy' or
`ACDEFGHIKLMNPQRSTVWY'.
Other letters will be converted to `X' and treated as unknown
amino acids.
Other characters, such as whitespace and
numbers, will simply be ignored.
- Include Graph: A graphic illustrating glycosylation potentials across the sequence length will
be generated (recommended).
- Show additional thresholds: Use this option if you want the graph to include
more thresholds than the default 0.5. These additional thresholds (0.32, 0.75, 0.90)
are used to assign higher confidence levels for positive and negative sites.
See more information in the Output Format notes.
- Choose the output format: Predict only on Asparagines that occur within
the Asn-Xaa-Ser/Thr triplet, or show output for all Asparagines in the sequence.
Note that predictions on Asparagines that do not occur within the Asn-Xaa-Ser/Thr
sequon are unlikely to be glycosylated, no matter what the prediction score.
The prediction method examines sequence context beyond the Asn-Xaa-Ser/Thr sequon
since both the positive and negative data sets only those Asparagines (to train
on) that occur in Asn-Xaa-Ser/Thr sequons. See more information in the Output Format notes.
- Press the "Submit sequence" button.
- A WWW page will return the results when the prediction is ready.
Response time depends on system load, but is usually only a few seconds.
Output format
# Predictions for N-Glycosylation sites in 1 sequence
Name: CBG_HUMAN Length: 405
(Sequence)
Asn-Xaa-Ser/Thr sequons (including Asn-Pro-Ser/Thr) are shown in blue.
Asparagines predicted to be N-glycosylated are shown in red.
Note that not all sequons are predicted glycosylated.
MPLLLYTCLLWLPTSGLWTVQAMDPNAAYVNMSNHHRGLASANVDFAFSLYKHLVALSPKKNIFISPVSISMALAMLSLG 80
TCGHTRAQLLQGLGFNLTERSETEIHQGFQHLHQLFAKSDTSLEMTMGNALFLDGSLELLESFSADIKHYYESEVLAMNF 160
QDWATASRQINSYVKNKTQGKIVDLFSGLDSPAILVLVNYIFFKGTWTQPFDLASTREENFYVDETTVVKVPMMLQSSTI 240
SYLHDSELPCQLVQMNYVGNGTVFFILPDKGKMNTVIAALSRDTINRWSAGLTSSQVDLYIPKVTISGVYDLGDVLEEMG 320
IADLFTNQANFSRITQDAQLKSSKVVHKAVLQLNEEGVDTAGSTGVTLNLTSKPIILRFNQPFIIMIFDHFTWSSLFLAR 400
VMNPV
(Annotation line)
`N' represents a predicted N-glycosylation site.
`n' represents an Asn with a positive score,
but not occuring within an Asn-Xaa-Ser/Thr sequon
..............................N................................................. 80
...............N................................................................ 160
................................................................................ 240
...................N............................................................ 320
................................................N............................... 400
.....
(Threshold=0.5)
--------------------------------------------------------------------------------
SeqName Position Potential Jury NGlyc
agreement result
--------------------------------------------------------------------------------
CBG_HUMAN 31 NMSN 0.7166 (9/9) ++ <-- Predicted as N-glycosylated (++)
CBG_HUMAN 96 NLTE 0.6356 (8/9) + <-- Predicted as N-glycosylated (+)
CBG_HUMAN 176 NKTQ 0.3941 (7/9) - <-- A negative site
CBG_HUMAN 260 NGTV 0.7400 (9/9) ++
CBG_HUMAN 330 NFSR 0.4223 (7/9) - see below for
CBG_HUMAN 369 NLTS 0.6684 (9/9) ++ more information
--------------------------------------------------------------------------------
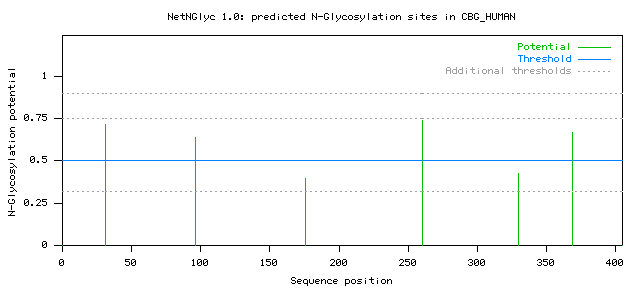
Graphics in PostScript
The graph illustrates predicted N-glyc sites across the protein chain
(x-axis represents protein length from N- to C-terminal). A position
with a potential (vertical lines) crossing the threshold (horizontal
line at 0.5) is predicted glycosylated. Additional thresholds are shown
at 0.32, 0.75 and 0.90 by horizontal dotted lines. Explained below.
An Encapsulated postscript format of the graph is available for
including in publications.
More Notes
The Asn-Xaa-Ser/Thr sequon
N-glycosylation is known to occur on Asparagines which occur in the
Asn-Xaa-Ser/Thr stretch (where Xaa is any amino acid except Proline).
While this consensus tripeptide (also called the N-glycosylation
sequon
in many texts) may be a requirement, it is not always sufficient for the
Asparagine to be glycosylated. Furthermore, there are a few known instances
of N-glycosylation occuring within Asn-Xaa-Cys (a Cysteine opposed to a Serine/Threonine
at the N+2 position) e.g. plasma protein C (
PRTC_HUMAN),
von Willebrand factor (
VWF_HUMAN).
NetNGlyc attempts to distinguish glycosylated sequons from non-glycosylated
ones. By default, predictions are only shown on Asn-Xaa-Ser/Thr sequons. If you choose
to predict on all Asparagines, then please be careful while interpreting the output.
From what we know so far, only asparagines within Asn-Xaa-Ser/Thr
(and in some cases, Asn-Xaa-Cys) are N-glycosylated
in vivo.
In the sequence output above, Asn-Xaa-Ser/Thr sequons are highlighted in
blue, and N-glycosylated Asparagines are
red. With the scores for each position, Asn-Xaa-Ser/Thr
sequons can be identified (in case prediction is made on all Asparagines) by
a 'SEQUON' note in the right margin.
Asn-Pro-Ser/Thr
Proline just after the Asparagine, is known to
preclude N-linked glycosylation in most cases by rendering the Asparagine
inaccessible. NetNGlyc has been trained to ignore this Proline position (to be
able to pick up other sequence signals). Thus, Asn-Pro-Ser/Thr triplets might be
predicted as glycosylated but a warning is generated. Such sites may only be
worth considering if there is additional confirmatory evidence.
Thresholds and confidence
Any potential crossing the default threshold of 0.5, represents a predicted
glycosylated site (as long as it occurs in the required sequon Asn-Xaa-Ser/Thr
without Proline at Xaa). The 'potential' score is the averaged output of
nine neural networks. For further information, the jury agreement column
indicates how many of the nine networks support the prediction. The
N-Glyc Result column shows one of the following outputs for predictions
indicating
glycosylated sites:
+ Potential < 0.5
++ Potential < 0.5 AND Jury agreement (9/9) OR Potential<0.75
+++ Potential < 0.75 AND Jury agreement
++++ Potential < 0.90 AND Jury agreement
and
non-glycosylated sites:
- Potential < 0.5
-- Potential < 0.5 AND Jury agreement (all nine > 0.5)
--- Potential < 0.32 AND Jury agreement
For picking up N-glycosylation sites with high specificity (Asparagines
very likely to be glycosylated), use only (++) predictions (and better) for
Asparagines that occur within the Asn-Xaa-Ser/Thr triplet (no Proline at the Xaa position).
Note that identifying sites this way would compromise sensitivity (you may
lose some positive sites).
Warnings and notes in the right margin
SEQUON ASN-XAA-SER/THR.
If you request a prediction on all Asparagines
(instead of the default to predict only on Asn-Xaa-Ser/Thr sequons), then this note will
appear for Asparagine positions which do occur within the Asn-Xaa-Ser/Thr sequon.
WARNING: PRO-X1.
Proline occurs just after the Asparagine residue. This makes it highly unlikely
that the Asparagine is glycosylated, presumably due to conformational constraints.
WARNING: PRO-X2.
Proline occurs at the 3rd position C-terminal to the Asparagine in question
(2nd 'X' in NX[ST]X). This makes it somewhat unlikely that the Asparagine is glycosylated,
but this condition is not as harsh as the PRO-X1 condition.
NetNGlyc Abstract
Contrary to widespread belief, acceptor sites for N-linked
glycosylation on protein sequences, are not well
characterised. The consensus sequence, Asn-Xaa-Ser/Thr
(where Xaa is not Pro), is known to be a prerequisite for
the modification. However, not all of these sequons are
modified and it is thus not discriminatory between
glycosylated and non-glycosylated asparagines. We train
artificial neural networks on the surrounding sequence
context, in an attempt to discriminate between acceptor and
non-acceptor sequons. In a cross-validated performance, the
networks could identify 86% of the glycosylated and 61% of
the non-glycosylated sequons, with an overall accuracy of
76%. The method can be optimised for high specificity
or high sensitivity. Apart from characterising individual
proteins, the prediction method can rapidly
scan complete proteomes.
Glycosylation is an important post-translational
modification, and is known to influence protein folding,
localisation and trafficking, protein solubility,
antigenicity, biological activity and half-life, as well as
cell-cell interactions. We investigate the spread of known
and predicted N-glycosylation sites across functional
categories of the human proteome.
CURRENT NETWORK
The network will be updated and predictions can alter due to different
versions. The network is balanced to give optimal predictions whether or not you
submit sequences with homology to the known N-glycosylated proteins.
If however the submitted sequence is very close to or identical to the
sequences in our training dataset, the accuracy can be expected to be higher
than reported above.
FEEDBACK, COMMENTS AND SUGGESTIONS:
We would appreciate any confirmation or the opposite of our predictions. Since
an expanded data set with additional N-glycosylated sequences would
increase the performance of the network, we are very interested in receiving
such material. User feedback is the only way we will learn to
enhance the performance of the method. Any other comments regarding
the predictions or the data may be sent to:
Ramneek Gupta
Software Downloads
- Version 1.0d
- Version 1.0d