Instructions/Help
The DeepLoc 2.0 server predicts the multi-label subcellular localization of eukaryotics proteins using Neural Networks algorithm trained on Uniprot proteins with experimental evidence of subcellular localization.
The model can predict whether a protein can be in one or multiple localizations inside the eukaryotic cell.
It only uses the sequence information to perform the prediction.
Additionally, DeepLoc 2.0 can predict the presence of the sorting signal(s) that had an influence on the prediction of the subcellular localization(s).
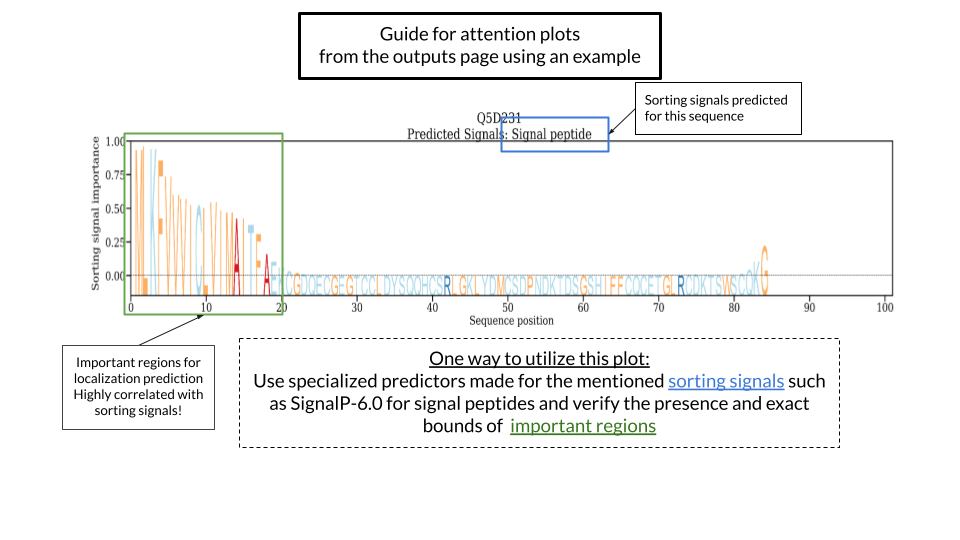
The importance of each amino acid in the predicted localization is also included as an "attention" plot.
Positions in the sequence with a high attention value are deemed more relevant for the prediction.
This does not mean that a particular amino acid is very important for the prediction but that a region in the neighbourhood of those positions has more weight in the final prediction of the model.
The DeepLoc 2.0 server can be run using two versions of the same model.
- The high-quality model utilizes the ProtT5-XL-Uniref50 transformer (ProtT5). This model provides a more accurate prediction at the expense of longer computation time due to the size of the model (3 billion parameters).
Use case: high-quality prediction for a small number of proteins.
- The high-throughput model utilizes the 33-layer ESM transformer (ESM1b). This smaller model (650 million parameters) has the advantage of a faster computation time with a slight decrease in accuracy compared to the ProtT5 model. Use case: high-throughput prediction for a larger number of proteins.
The DeepLoc 2.0 server requires protein sequence(s) in fasta format, and can not handle nucleic acid sequences.
Two different versions of the output can be selected before running DeepLoc 2.0. The long output will generate an attention plot per sequence while the short output will not generate any plots.
Paste protein sequence(s) in fasta format or upload a fasta file.
After the server successfully finishes the job, a summary page shows up.
If an error happens during the prediction a log will appear specifying the error.
Output format
The DeepLoc 2.0 output is composed of three main components:
- The Predicted localizations and Predicted signals display the subcellular localizations and sorting signals predicted for the query protein, respectively.
- The Probability table displays the probability assigned by the model to each of the subcellular localizations. Localizations with a probability above the threshold are highlighted in green. The green intensity reflects the proximity of the localization probability to the threshold. The intensity increases the farther the probability is from the threshold.
- The Sorting signal importance displays a logo-like plot of the positions in the query protein with higher importance for the prediction and highly associated with sorting signals.
Training and testing data sets
The dataset used to train and test the DeepLoc 2.0 server is available here:
The
Partition column in the Training/Validation set indicates the five partitions (0-4) that the dataset was homology partitioned (maximum 30% sequence similarity).
References
Please cite:
DeepLoc 2.0: multi-label subcellular localization prediction using protein language models.
Vineet Thumuluri, Jose Juan Almagro Armenteros, Alexander Rosenberg Johansen, Henrik Nielsen, Ole Winther.
Nucleic Acids Research, Web server issue 2022.
Abstract
The prediction of protein subcellular localization is of great relevance for proteomics research.
Here, we propose an update to the popular tool DeepLoc with multi-localization prediction and improvements in both performance and interpretability.
For training and validation, we curate eukaryotic and human multi-location protein datasets with stringent homology partitioning and enriched with sorting signal information compiled from the literature. We achieve state-of-the-art performance in DeepLoc 2.0 by using a pre-trained protein language model. It has the further advantage that it uses sequence input rather than relying on slower protein profiles. We provide two means of better interpretability: an attention output along the sequence and highly accurate prediction of nine different types of protein sorting signals. We find that the attention output correlates well with the position of sorting signals.